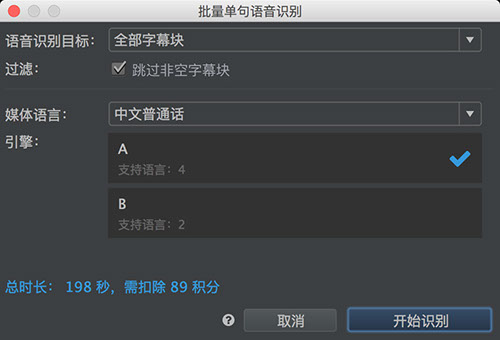
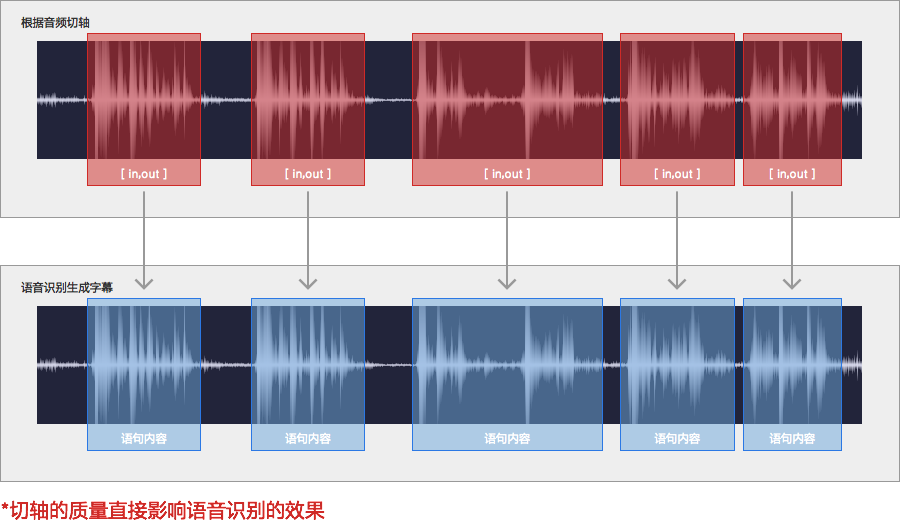
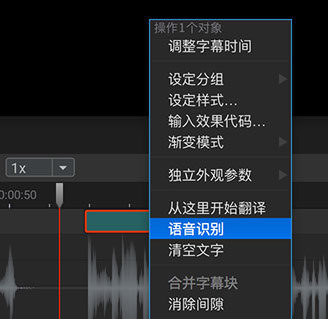
可以将每个字幕块对应的音频片段,识别为文本,并填充到该字幕块中,识别后需要人工校对。语音识别属于按量付费功能,需要联网并登陆使用,24小时内的扣费会聚合显示为一条记录。识别失败的句子不计费,但同一段话重复识别会重复扣费。
*推荐使用更好用智能的全自动语音转写功能,如果觉得单句识别的流程麻烦,可使用新功能。
使用教程 >
▪ 单句语音识别功能
可以将每个字幕块对应的音频片段,识别为文本,并填充到该字幕块中,识别后需要人工校对。语音识别属于按量付费功能,需要联网并登陆使用,24小时内的扣费会聚合显示为一条记录。识别失败的句子不计费,但同一段话重复识别会重复扣费。
*推荐使用更好用智能的全自动语音转写功能,如果觉得单句识别的流程麻烦,可使用新功能。
操作方法:
有若干引擎可供选择,不同引擎所支持的语言及准确率稍有不同。大家可以根据自身情况灵活的选用。
*说明:如果识别过程中由于网络不畅或积分不足导致扣费失败,任务会自动中断。请在检查网络或充值后,继续识别后面未完成的句子。